informatica transformation - dynamic lookup
Updated at: August 19, 2017
if row_count of table/file which you lookup > 1 million, I suggest you to use joiner instead of lookup.
What is Dynamic Lookup?
When lookup used Dynamic Cache then it’s called as a Dynamic Lookup.
What is Dynamic Cache?
Dynamic Cache may get updated during mapping run. Means new records would be inserted and updated records would be updated in cache during mapping run.
How to create Dynamic Looup
Lookup Transformation -> Right Click Edit Properties Tab Dynamic Lookup Cache Option (Check) (Check box should be check)
Properties of Dynamic Lookup
- NewLookupRow You will get this default port as soon as you checked option for dynamic lookup. In this port you will get three values 0 (For No Operation at Cache) 1 (If record inserted into Cache) 2 (If record Updated in Cache)
- Associated Expression This option we need to set for each and every lookup port means if you have checked all port as lookup port then we need to set associated port for each and every lookup port. (Basically value in lookup port compared with value of Associated Expression to decide whether Lookup Cache has to insert or update, If so then Lookup Cache will be updated with value of Associated port.)
- Lookup SQL Override Yahoo!!! Here also, we can override SQL according to our need; If Lookup table is relational table.
For Updating Lookup Cache we need to set some more properties
You can choose either of option according to your need:
- Insert Else Update
- Update Else Insert
(OMG!!! Isn’t both options are same?) It’s totally depends upon row type, means which type of rows are entering to lookup, is it insert or update. Ex: I have use update Strategy before lookup and based upon some condition I am flagging record as DD_UPDATE then row type becomes as update. So, in a simple word if you are passing records from update strategy with (DD_UPDATE) to Lookup then Choose Update Else Inset otherwise choose Insert Else Update. Be careful while choosing this option otherwise your cache won’t update L
- Output Old Value on Update Check box option… Select it according to your requirement if you need lookup to return old value after updating cache with new value.
- Update Dynamic Cache Condition Through this option we can develop expression. When an expression evaluation is true then only update Cache. Ex: (Source_Sal!= LKP_Sal)
Yes, now we have power. Thank you, Informatica. Means before 9.x this option was not available. L
A LookUp cache does not change its data once built. But what if the underlying table upon which lookup was done changes the data after the lookup cache is created? Is there a way so that the cache always remain up-to-date even if the underlying table changes?
Lookup connection
Connection value of lookup transformation only allows two kinds of values at mapping level: 1. Hard code(e.g. Relational:PC_DELPDW_DEV_DELL_PDW_SQL06) 2. System built-in connection variable(e.g. $Target/$Source) And these values can propagate to corresponding session.
User defined connection variable(e.g. $DBConnection_pdw_dev) can’t be recognized at mapping level, but you can set it at session level. That’s why connection value don’t propagate after refresh session mapping. ‘$DBConnection_pdw_dev’ is useless at mapplet.
Why do we need Dynamic Lookup Cache?
Let’s think about this scenario. You are loading your target table through a mapping. Inside the mapping you have a Lookup and in the Lookup, you are actually looking up the same target table you are loading.
You may ask me, “So? What’s the big deal? We all do it quite often…”. And yes you are right.
There is no “big deal” because Informatica (generally) caches the lookup table in the very beginning of the mapping, so whatever record getting inserted to the target table through the mapping, will have no effect on the Lookup cache.
The lookup will still hold the previously cached data, even if the underlying target table is changing.
But what if you want your Informatica Lookup cache to get updated as and when the data in the underlying target table changes?
What if you want your lookup cache to always show the exact snapshot of the data in your target table at that point in time? Clearly this requirement will not be fullfilled in case you use a static cache. You will need a dynamic cache to handle this.
But in which scenario will someone need to use a dynamic cache? To understand this, let’s first understand a static cache scenario.
Static Lookup Cache Scenario
Let’s suppose you run a retail business and maintain all your customer information in a customer master table (RDBMS table). Every night, all the customers from your customer master table is loaded in to a Customer Dimension table in your data warehouse. Your source customer table is a transaction system table, probably in 3rd normal form, and does not store history. Meaning, if a customer changes his address, the old address is updated with the new address.
But your data warehouse table stores the history (may be in the form of SCD Type-II). There is a map that loads your data warehouse table from the source table. Typically you do a Lookup on target (static cache) and check with every incoming customer record to determine if the customer is already existing in target or not. If the customer is not already existing in target, you conclude the customer is new and INSERT the record whereas if the customer is already existing, you may want to update the target record with this new record (if the record is updated). This scenario - commonly known as ‘UPSERT’ (update else insert) scenario - is illustrated below.

A static Lookup Cache to determine if a source record is new or updatable
You don’t need dynamic Lookup cache for the above type of scenario.
Dynamic Lookup Cache Scenario
Notice in the previous example I mentioned that your source table is an RDBMS table. Generally speaking, this ensures that your source table does not have any duplicate record.
But, What if you had a flat file as source with many duplicate records in the same bunch of data that you are trying to load? (Or even a RDBMS table may also contain duplicate records) Would the scenario be same if the bunch of data I am loading contains duplicate?
Unfortunately Not. Let’s understand why from the below illustration. As you can see below, the new customer “Linda” has been entered twice in the source system - most likely mistakenly. The customer “Linda” is not present in your target system and hence does not exist in the target side lookup cache.
When you try to load the target table, Informatica processes row 3 and inserts it to target as customer “Linda” does not exist in target. Then Informatica processes row 4 and again inserts “Linda” into target since Informatica lookup’s static cache can not detect that the customer “Linda” has already been inserted. This results into duplicate rows in target.
A Scenario illustrating the use of dynamic lookup cache

The problem arising from above scenario can be resolved by using dynamic lookup cache
Here are some more examples when you may consider using dynamic lookup,
- Updating a master customer table with both new and updated customer information coming together as shown above
- Loading data into a slowly changing dimension table and a fact table at the same time. Remember, you typically lookup the dimension while loading to fact. So you load dimension table before loading fact table. But using dynamic lookup, you can load both simultaneously.
- Loading data from a file with many duplicate records and to eliminate duplicate records in target by updating a duplicate row i.e. keeping the most recent row or the initial row
- Loading the same data from multiple sources using a single mapping. Just consider the previous Retail business example. If you have more than one shops and Linda has visited two of your shops for the first time, customer record Linda will come twice during the same load.
How does dynamic lookup cache work
Once you have configured your lookup to use dynamic cache (we will see below how to do that), when Integration Service reads a row from the source, it updates the lookup cache by performing one of the following actions:
- Inserts the row into the cache: If the incoming row is not in the cache, the Integration Service inserts the row in the cache based on input ports or generated Sequence-ID. The Integration Service flags the row as insert.
- Updates the row in the cache: If the row exists in the cache, the Integration Service updates the row in the cache based on the input ports. The Integration Service flags the row as update.
- Makes no change to the cache: This happens when the row exists in the cache and the lookup is configured or specified To Insert New Rows only or, the row is not in the cache and lookup is configured to update existing rows only or, the row is in the cache, but based on the lookup condition, nothing changes. The Integration Service flags the row as unchanged.
Notice that Integration Service actually flags the rows based on the above three conditions. NewLookupRow
Configure Dynamic Lookup Mapping - Example
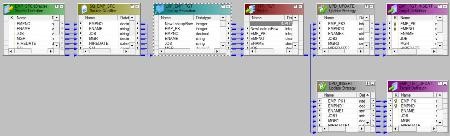



Dynamic Lookup Sequence ID
While using a dynamic lookup cache, we must associate each lookup/output port with an input/output port or a sequence ID. The Integration Service uses the data in the associated port to insert or update rows in the lookup cache. The Designer associates the input/output ports with the lookup/output ports used in the lookup condition.
When we select Sequence-ID in the Associated Port column, the Integration Service generates a sequence ID for each row it inserts into the lookup cache.
When the Integration Service creates the dynamic lookup cache, it tracks the range of values in the cache associated with any port using a sequence ID and it generates a key for the port by incrementing the greatest sequence ID existing value by one, when the inserting a new row of data into the cache.
When the Integration Service reaches the maximum number for a generated sequence ID, it starts over at one and increments each sequence ID by one until it reaches the smallest existing value minus one. If the Integration Service runs out of unique sequence ID numbers, the session fails.
Dynamic Lookup Ports
The lookup/output port output value depends on whether we choose to output old or new values when the Integration Service updates a row:
- Output old values on update: The Integration Service outputs the value that existed in the cache before it updated the row.
- Output new values on update: The Integration Service outputs the updated value that it writes in the cache. The lookup/output port value matches the input/output port value.
Note: We can configure to output old or new values using the Output Old Value On Update transformation property.
Handling NULL in dynamic LookUp
If the input value is NULL and we select the Ignore Null inputs for Update property for the associated input port, the input value does not equal the lookup value or the value out of the input/output port. When you select the Ignore Null property, the lookup cache and the target table might become unsynchronized if you pass null values to the target. You must verify that you do not pass null values to the target.
When you update a dynamic lookup cache and target table, the source data might contain some null values. The Integration Service can handle the null values in the following ways:
- Insert null values: The Integration Service uses null values from the source and updates the lookup cache and target table using all values from the source.
- Ignore Null inputs for Update property : The Integration Service ignores the null values in the source and updates the lookup cache and target table using only the not null values from the source.
If we know the source data contains null values, and we do not want the Integration Service to update the lookup cache or target with null values, then we need to check the Ignore Null property for the corresponding lookup/output port.
When we choose to ignore NULLs, we must verify that we output the same values to the target that the Integration Service writes to the lookup cache. We can Configure the mapping based on the value we want the Integration Service to output from the lookup/output ports when it updates a row in the cache, so that lookup cache and the target table might not become unsynchronized.
- New values. Connect only lookup/output ports from the Lookup transformation to the target.
- Old values. Add an Expression transformation after the Lookup transformation and before the Filter or Router transformation. Add output ports in the Expression transformation for each port in the target table and create expressions to ensure that we do not output null input values to the target.
Some other details about Dynamic Lookup
When we run a session that uses a dynamic lookup cache, the Integration Service compares the values in all lookup ports with the values in their associated input ports by default.
It compares the values to determine whether or not to update the row in the lookup cache. When a value in an input port differs from the value in the lookup port, the Integration Service updates the row in the cache.
But what if we don’t want to compare all ports?
We can choose the ports we want the Integration Service to ignore when it compares ports. The Designer only enables this property for lookup/output ports when the port is not used in the lookup condition. We can improve performance by ignoring some ports during comparison. (Learn how to improve performance of lookup transformation here)
We might want to do this when the source data includes a column that indicates whether or not the row contains data we need to update. Select the Ignore in Comparison property for all lookup ports except the port that indicates whether or not to update the row in the cache and target table.
Note: We must configure the Lookup transformation to compare at least one port else the Integration Service fails the session when we ignore all ports.