TD cases of reducing CPU consumption
Updated at: February 28, 2017
shared by suichen @ebay
Case Study 1: Reduce Frequency
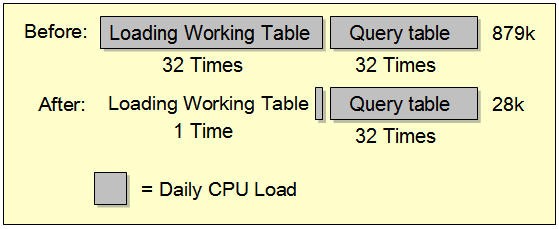
- Reduce frequency of loading working tables
- Scenario Instance: Running the same scripts 32 times to load a working table in a week where the change of data in the working table is very minimal
- Proposed solution: Loading of working table takes place once every week and query off from that table can be as frequent as possible
- CPU savings: Save 879K * 31/32 = 868K on weekly base
Case 2: Enhance Large Tables Join
- Explicitly specify filter condition on table join
- Scenario Instance: Joining lstg_item and feedback_detail tables where item_site_id is zero. The query uses ONLY the following condition,
AND dw_lstg_item.item_site_id = 0 /* only US */ - Proposed Solution: Explicitly add the same condition on the feedback_detail table
AND dw_feedback_detail.item_site_id = 0 /*New */ - CPU savings: Save 1MM CPU seconds (32% of savings) on weekly basis (Also fixes upstream data quality issue - item_site_id is null on dw_feedback_detail table)
Case Study 3: Reduce Data Scan by Partition
The Partitioned Primary Index (PPI) feature enables you to set up databases that provide performance benefits from data locality, while retaining the benefits of scalability inherent in the hash architecture of Teradata Database.
PPI improves performance as follows:
- Uses partition elimination (static, delayed, or dynamic) to improve the efficiency of range searches when, for example, the searches are range partitioned.
- Provides an access path to the rows in the base table while still providing efficient join strategies.
Explicitly add static filter condition before joining
Interval function:
- For date ‘2006-10-23’ – interval ’23’ month the partition eliminate enabled.
- For date ‘2006-10-23’ – 23 the partition eliminate enabled.
- For current_date – interval ‘23’ month, the parathion eliminate enabled.
- For current_date, the parathion eliminate enabled.
Explicitly add partition condition on two PPI tables with identical partitioning expressions joining
When two PPI tables joining with identical PPI column, need add PPI filter to enable rowkey-based PPI joining.
Scenario Instance: Joining DW_LSTG_ITEM and LSTG_ITEM_COLD tables without leveraging the PPI of the tables.
Proposed Solution: Leverage the AUCT_END_DT PPI column in the join condition as in the following,
SELECT ... FROM dw_lstg_item hot JOIN dw_lstg_item_cold cold
ON hot.item_id = cold.item_id
AND hot.auct_end_dt = cold.auct_end_dt
PU Savings: 3.8 MM Out of Original 6.1 MM Total CPU (Weekly)
Explicitly add partition condition on a PPI table to an NPPI table or two PPI tables with different partitioning expressions joining
Define two PPI tables with different partition expressions first: Any non-identical expression of PPI from two tables. illustrated in table 1
PARTITION BY RANGE_N(SESSION_SRC_CRE_DT BETWEEN DATE '2007-01-05'
AND DATE '2010-12-31' EACH INTERVAL '1' DAY ,NO RANGE);
PARTITION BY RANGE_N(session_src_cre_dt BETWEEN DATE '2006-11-17'
AND DATE '2010-12-31' EACH INTERVAL '1' DAY ,NO RANGE);
table 1 two different PPI column expression
The Optimizer has three general approaches to this kind of joining :
- spool the PPI table (or both PPI tables) into an NPPI spool file in preparation for a traditional merge join.(relatively low performance)
- spool the NPPI table (or one of the two PPI tables) into a PPI spool file, with identical partitioning to the remaining table, in preparation for a rowkey-based merge join.(high performance)
- use the sliding-window join of the tables without spooling either one. (relatively low performance)
Dynamic SQL
PPI filter condition do improve the query performance, but the precondition is that the condition(criterion) is specified literally, e.g
LSTG_ITEM.AUCT_END_DT = DATE '2010-09-03' or LSTG_ITEM.AUCT_END_DT BETWEEN DATE '2010-09-01' AND DATE '2010-09-02'
However,there some cases cannot provide literal PPI filter condition straightforwardly. See the following code from a real batch job:
INSERT INTO DW_UM_USER_SMPL_MAP_V ( USER_SMPL_MAP_ID ,USER_ID ,
GUID ,SITE_ID ,SESSION_ID ,CAL_DT )
SELECT USER_SMPL_MAP_ID ,USER_ID ,GUID ,SITE_ID ,SESSION_ID ,CAL_DT
FROM batch_views.DW_UM_USER_SMPL_MAP MP, (
SELECT MIN(AD_EVENT_CRE_DT) MIN_DT, MAX(AD_EVENT_CRE_DT) MAX_DT FROM batch_views.DW_UM_SMPL_AD_MTRC_I )A
WHERE MP.CAL_DT BETWEEN A.MIN_DT AND A.MAX_DT;
The obstacle is that the date range is dynamically determined by the data within integration(working) table. We cannot leverage the PPI(column CAL_DT), search against the large table(DW_UM_USER_SMPL_MAP) by a way of all-rows scan, therefore cost much CPU time.
We figure out this by means of an approach named as “dynamic SQL”. We issue a select SQL to generate another SQL, see the “dynamic SQL” for the above SQL
SELECT '
INSERT INTO DW_UM_USER_SMPL_MAP_V ( USER_SMPL_MAP_ID ,USER_ID ,
GUID ,SITE_ID ,SESSION_ID ,CAL_DT )
SELECT USER_SMPL_MAP_ID ,USER_ID ,GUID ,SITE_ID ,SESSION_ID ,CAL_DT
FROM batch_views.DW_UM_USER_SMPL_MAP MP
WHERE MP.CAL_DT BETWEEN DATE''' || MIN_DT || ''' AND ''' || MAX_DT || ''';' (TITLE '')
FROM (
SELECT
CAST(CAST(MIN(AD_EVENT_CRE_DT) AS FORMAT 'YYYY-MM-DD') AS CHAR(10)) AS MIN_DT ,
CAST(CAST(MAX(AD_EVENT_CRE_DT) AS FORMAT 'YYYY-MM-DD') AS CHAR(10)) AS MAX_DT
FROM
batch_views.DW_UM_SMPL_AD_MTRC_I
)A;
It results the ultimate SQL which should be execute exactly.
INSERT INTO DW_UM_USER_SMPL_MAP_V ( USER_SMPL_MAP_ID ,USER_ID ,
GUID ,SITE_ID ,SESSION_ID ,CAL_DT )
SELECT USER_SMPL_MAP_ID ,USER_ID ,GUID ,SITE_ID ,SESSION_ID ,CAL_DT
FROM batch_views.DW_UM_USER_SMPL_MAP MP
WHERE MP.CAL_DT BETWEEN DATE'2010-07-31' AND '2010-08-31';
Now, only 6 partitions of MAP table are scaned, dramatically reduce the CPU consumption(from 41k to 4k).
Case Study 4: Reduce Data Scan by Logical Elimination
- Explicitly apply PPI condition by considering data element relationship logical rules
Scenario Instance: Query Listing Items from DW_LSTG_ITEM_COLD table by Site_Create_Date without leveraging the PPI column
Select ... from DW_LSTG_ITEM_COLD where DW_LSTG_ITEM_COLD.SITE_CREATE_DATE>= '2008-10-26 00:00:00' - Proposed Solution: Apply the PPI column (auct_end_dt) as part of the filter condition base on the business logic that auct_end_dt should always be later than site_create_date.
Select ... from DW_LSTG_ITEM_COLD where DW_LSTG_ITEM_COLD.SITE_CREATE_DATE>= '2008-10-26 00:00:00' and (item.auct_end_dt >= '2008-10-26' OR item.auct_end_dt = '1969-12-31')
CPU savings: 800k (weekly)
Case Study 5: Handle Non Equality Constraints in Where Clause
For any non equality constraints in SQL Where clause such as IN, NOT IN, LIKE, BETWEEN, >, <, >=, <=, specifying the constraints properly will enhance the performance of the SQL.
Example: Explicitly apply non equality constraints condition to all related columns.
-
Before explicitly apply non equality constraints condition, the SQL looks like
where a = b = c AND a is like '%apple%' -
During performance tuning, the where clase has been updated as:
where a is like '%apple%', b is like '%apple%', c is like '%apple%' and a = b = c -
The performance has been improved after explicitly specifying the non equality constraints.
Case 8: Merge-into for Upsert
Syntax Extension
MERGE [INTO] tablename [ [AS] aname ]
{ VALUES (expr [...,expr]) }
USING { } [AS] source_tname (cname, [...,cname])
{ ( subquery ) }
ON match-condition
WHEN MATCHED THEN
UPD[ATE] SET cname = expr [...,cname = expr]
WHEN NOT MATCHED THEN
{ [VALUES] (expr [...,expr] ) }
INS[ERT] { }
{ (cname [...,cname]) VALUES (expr [...,expr]) }
{ ALL [except_option] }
LOGGING [{ }] ERRORS [error_limit_option]] ;
{ DATA }
Where error_limit_option is
{ NO LIMIT }
[WITH { }]
{ LIMIT OF }
and except option is
{ REFERENCING }
[EXCEPT { }]
{ UNIQUE INDEX }
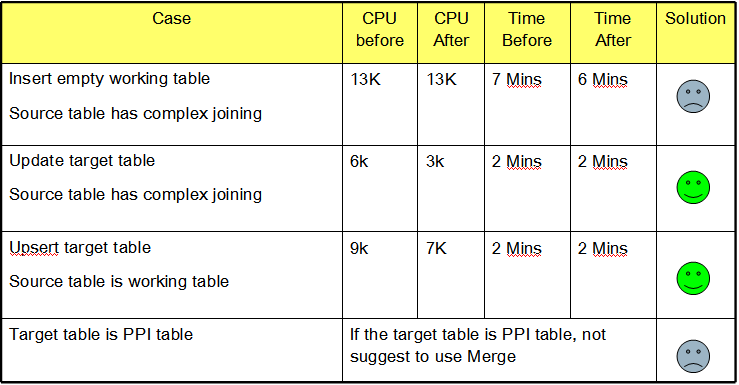
Cases Performance Result
MERGE INTO ${workingDB}.DW_MYEBAY_WTCHD_DSCT_ITEM_W E
USING (
SELECT B.ITEM_ID, B.AUCT_END_DT, C.ITEM_SITE_ID, C.LEAF_CATEG_ID, D.CATEG_LVL2_ID, B.AUCT_TITL
FROM ${gdwDB}.DW_LSTG_ITEM C, ${gdwDB}.DW_LSTG_ITEM_COLD B, ${gdwDB}.DW_CATEGORY_GROUPINGS D
WHERE B.ITEM_ID = C.ITEM_ID
AND B.AUCT_END_DT = C.AUCT_END_DT
AND C.AUCT_END_DT >= '$START_DATE'
)B
ON E.ITEM_ID = B.ITEM_ID
AND E.PRCS_FLAG IS NULL
WHEN matched THEN
UPDATE SET PRCS_FLAG = 1 ,
AUCT_END_DT = B.AUCT_END_DT ,
ITEM_SITE_ID = B.ITEM_SITE_ID ,
ITEM_LEAF_CATEG_ID = B.LEAF_CATEG_ID ,
CATEG_LVL2_ID = B.CATEG_LVL2_ID ,
CATEG_LVL3_ID = B.CATEG_LVL2_ID ,
WATCH_AUCT_TITLE_TXT = SUBSTR ( B.AUCT_TITL , 1 , 50 );
Result: